




Aspergillus insolitus
Aspergillus insolitus
规格:
货期:
编号:TS1002300
品牌:Testobio
| Product name: | Aspergillus insolitus |
| Testo id: | TS1002300 |
| Species Name: | Aspergillus insolitus |
| Type: | Polypaecilum insolitum |
| Synonyms: | Polypaecilum insolitum / Scopulariopsis divaricata / Scopulariopsis divaricata var. alba / Scopulariopsis insolita |
| Taxonomy: | FUNGI Ascomycota, Eurotiomycetes, Eurotiales, Aspergillaceae |
| Strain History: | C.J. La Touche (No. SC150) -> CBS 384.61 -> UAMH |
| Substrate: | ear, man |
| Isolator: | C.J. La Touche (No. SC150) |
| Isolation Date: | 1961-11-01 |
| Date Received: | 2010-08-03 |
| Characters: | CULTURE CONDITIONS grows better @ 30C than @ 35C - fide UAMH 2010 // MOLECULAR SYSTEMATICS phylogeny of Penicillium and related taxa in the Trichocomaceae - Houbrakken J, Samson RA, Stud Mycol 70:1-51, 2011 // PIGMENT yellow on PDA |
| Compounds: | |
| Cross Reference: | ATCC 18164 // CBS 384.61 // IFO 8788 // IMI 075202 // LSHB BB414 // MUCL 3078 // QM 7961 |
| Pathogenic Potential: | Human: yes | Animal: yes | Plant: no |
| Biosafety Risk Group: | RG2 (check the PHAC ePATHogen Risk Group Database for updates) |
| Regulatory Requirements: | Canadian requesters must provide PHAC Pathogen and Toxin License Number (see: https://www.canada.ca/en/public-health/services/laboratory-biosafety-biosecurity/licensing-program.html) prior to shipment. International requesters must provide all legally required importation documentation prior to shipment. Plant pathogenicity status may be verified by using the USDA Agricultural Research Service (ARS) Fungal Database |
| MycoBank ID: | 809591 |
| Sequences: | >UAMH11254_JN121911_Cct8 ACCCAGAAGGCCAAGGTGGGCGTGTTTAGCTGCCCAATTGATGTTAGCCAGACCGAGACCAAGGGAACAGTGCTTTTGAAGAACGCGCAGGAGATGCTCGACTACACTAAGGGAGAGGAGGAACGTCTTGAGGCGGCTATCAAGGAACTCTACGATTCGGGGATTCGTGTGGTCGTTGCGGGTGCGACTGTCGGTGACCTAGCTCTCCACTACCTTAACCGCTTCAATATTCTTGTGATTAAGATCTTGTCGAAGTTCGAGCTCCGCCGACTCTGCCGTGTCGTCGGTGCTACGCCTCTTGCTCGTTTGGGGGCACCTATGCCGGACGAGATGGGTAGCGTGGATGTGGTCGAGACCACGGAAATTGGCGGAGACCGAGTCACCGTGTTCCGTCAAGAAGACCCCAACACTGTCACACGCACAGCTACCATCGTCCTGCGTGGAGCGACCCAGAACCACCTGGAGGACGTCGAGCGTGCTATTGACGACGGGGTTAACGCTATCAAAGCGATCACCAAGGACCCGCGTCTCGTTCCTGGCGCTGGAGCCACTGAGATCCAGCTCTTAGAACGAATCTCGGCGTTTGCGGACAAGACGCCTGGGCTACCCCAGCATGCGATTCGGAAGTTCGCCGAGGCGTTCGAAGTGATTCCTCGTACGCTTGCCGAGTCTGCCGGGTTAGATGCCACGGAGGTGCTTTCTCGCCTGTACACA >UAMH11254_ITS CATTACCGAGCGTTTGGCAGCCCTGTTCCAGGGTTGCCTACCTCCCACCCGTGACTACCGTACCTTGTTGCTTCGGCGGGCCGCCGTCAGGCCCCCGGGGCGGGGGAGAAATCCCCCCCCTTCCGGGGCAGCGCCCGCCGGAGACACCTTGAAACTCTTTGTGTGAAGATTGCCTCTGAGTTTGACACAAAATAGCCAAAACTTTCAACAACGGATCTCTTGGTTCCGGCATCGATGAAGAACGCAGCGAACTGCGATAAGTAATGTGAATTGCAGAATTCAGTGAATCATCGAGTCTTTGAACGCACATTGCGCCCCCTGGTATTCCGGGGGGCATGCCTGTCCGAGCGTCATTGCTACCCTCCAGCACGGCTGGTGTGTTGGGCGCCGCGTCCCCTCCCCTTCCGGGGGGGACGGGCCCGAAAGGCAGCGGCGGCACCGTCCGGTCCTCGAGCGTATGGGGCTTTGTCACCCGCTCTGCAGGGCCGGCCGGGGCTCGCCTCGACAGTCAGTCTTCTTTTTTTTCTAAGGTTGACCTCGGATCAGGTAGGGATACCCGCTGAACTT >UAMH11254_JN121667_RNA polymerase II GTGTCTCCACAGCGAAATGGTCCCCTCATGGGTATTGTGCAAGATACCCTTTGTGGTATCTACAAGATTTGTCGGCGTGACGTTTTCCTATCCAGAGAACAAGTGATGAATATCATGCTCTGGGTTCCAGACTGGGATGGTGTTCTGCCACCGCCAGCTATTGTGAAGCCTCGGCCGCGATGGACCGGGAAGCAGATGATTAGCATGGCGCTTCCATCGGGTCTGAACCTCCTTCGTGTCGACAAGGACAATTCGGCTCTCTCCGAGAAGTTTTCCCCTCTTAACGATGGCGGATTGCTCATACACAGTGGACAGGTGATGTATGGAATGTTCTCTAAGAAGACTGTTGGCGCTAGTGGTGGTGGCGTTGTCCATACCATTTACAATGAGTATGGACCAGATGCTGCTGTCGCTTTCTTCAACGGCGCTCAGACCATTGTCAACTACTGGTTGTTACATCATGGGTTCAGTATTGGCATTGGCGACACGATTCCGGATCCGTCCACGATTCAGAGAATCGAGAATTGTGTTCGCAACCGCAAACAGGAAGTCGAATCTATAACCGCGAGTGCGACTGATAACACTCTCGAGGCGTTACCCGGTATGAATGTGCGAGAAACTTTCGAAAGCAAGGTCTCGCGTGCCCTCAACAATGCCCGTGATGAAGCTGGTGGCGAAACCGAGAAGAGCTTGAAGGATCTTAACAACGCCATCCAGATGGCACGTTCTGGATCCAAGGGATCGACTATTAACATTTCCCAGATG >UAMH11254_JN121510_RNA polymerase II AGGTGTGTTGAGAGTGGCAAGGATATTTATATGAATATTGGTGTAAAGGCCAGCACGTTGAGCTCGGGCTTGAAGTATGCTCTTGCCACAGGAAACTGGGGTGAGCAGAAGAAGGCAGCAAGCTCGAAGGCTGGTGTGTCGCAAGTACTCAGTCGATACACCTACGCGTCTACATTGTCACATCTTCGCCGGACCAACACGCCCATCGGCCGTGACGGAAAGATCGCGAAGCCACGCCAGCTTCACAACACGCACTGGGGCTTGGTCTGTCCGTCCGAAACTCCGGAAGGTCAAGCCTGCGGTCTCGTGAAGAATCTGGCGCTCATGTGCTACATCACCGTTGGTACGCCCAGCGAGCCGATCATCGACTTCATGATCCAGCGCAACATGGAGGTACTCGAGGAGTTCGAGCCCCAGGTGACGCCGAATGCAACAAAGGTGTTTGTGAACGGTGTCTGGGTAGGAATCCACCGTGATCCGTCTCATCTTGTTAACACCATGCTGTCGCTGCGCCGGCGGAACATGATTTCGCACGAGGTCAGTTTGATTCGGGACATCCGAGAGCGGGAGTTCAAGATCTTCACGGATGCCGGCCGTGTATCACGACCGCTGTTCGTTATCGACAACGACCCGAAGAGCGAGAACTCCGGCTCGTTAGTCCTTAATAAAGAGCATATCCGTAAATTGGAGGAAGATAAGGAATTGCCGCCCGACCTGGACCCCGAAGAGCGGAGAGAGCGCTATTTCGGATGGGATGGTCTTGTCAAATCTGGAGTTGTCGAATATGTCGATGCTGAGGAAGAGGAGACGATCATGATCGTGATGACCCCTGAAGACCTCGAGATCTCCAAGCAGCTTCAGGCCGGATATGCTCTTCCCGTGGAGACGGATCCGCACAAGCGAGTCCGGTCGATTCTCACGCAAAGGGCACATACGTGGACGCACTGCGAA >UAMH11254_JN121816_Tsr1 CTGAGTCGGTGGGAGACATCCGAGGACCGCCCACACGAACCTGAAGATTGGCGTCGACTGCTTCAAATTGCTGATTATAAGGGCTCCAAAAACAAGGCTATCAGAGAAGCACTGGTTGGAGGTGTCGACCCTGGAAACCGTGTCGACGTTCACCTTCGGGCAGTACCAGCATCCCTTCGCAATCGGCCACAGCCAGTGTCCCTTTTCTCCCTCCTCCGCCATGAGCACAAACAGACAGTTGTCAACATAAGCATGTACCTCCACTCTGACGTCGAGGCACCCCTGAAGTCTAAGGAAGAGCTTCTCATCCAATGCGGACCACGCCGTCTGGTCGTGAACCCTATCTTTTCCGCCGGAGGCGTGACTCCAAACAACGTCCACAAATTCGACCGCTTCCTCCACCCCGGCCGGAGTGCCATCGCATCCTGGATCGGGCCTATGACCTGGGGTTCAGTGCCTGCCCTCGTCTTCAAAAACAAGCAAGTCCAAGACCCCGAAGTGATGGACTCAGCCGACGAAAACTCCGAGAACAAACCGACCATCGACCAACTGCAGCTGATCGGAACCGGAACCGTCGTCGCGCCTGACCAGTCTCGAGTCGTCGCCAAGCGAGCTATC |
首页/产品中心/进口菌株
产品中心
联系我们 CONTACT US
0574-87917803
testobio@163.com
浙江省宁波市镇海区庄市街道兴庄路9号
创e慧谷42号楼B幢401室
最新促销




Aspergillus insolitus
Aspergillus insolitus
规格:
货期:
编号:TS1002300
品牌:Testobio
标准菌株
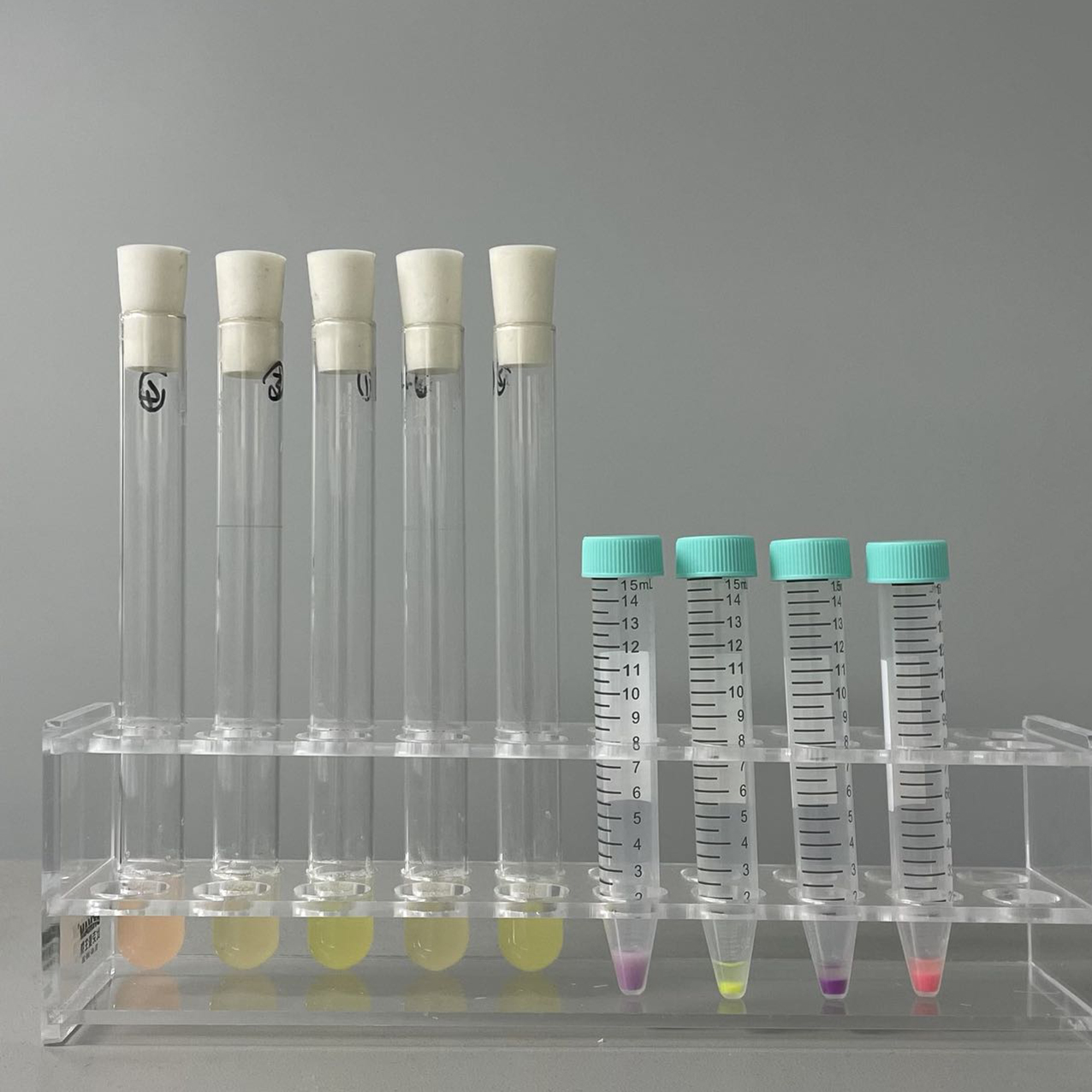
定量菌液
DNA
RNA
规格:
冻干粉
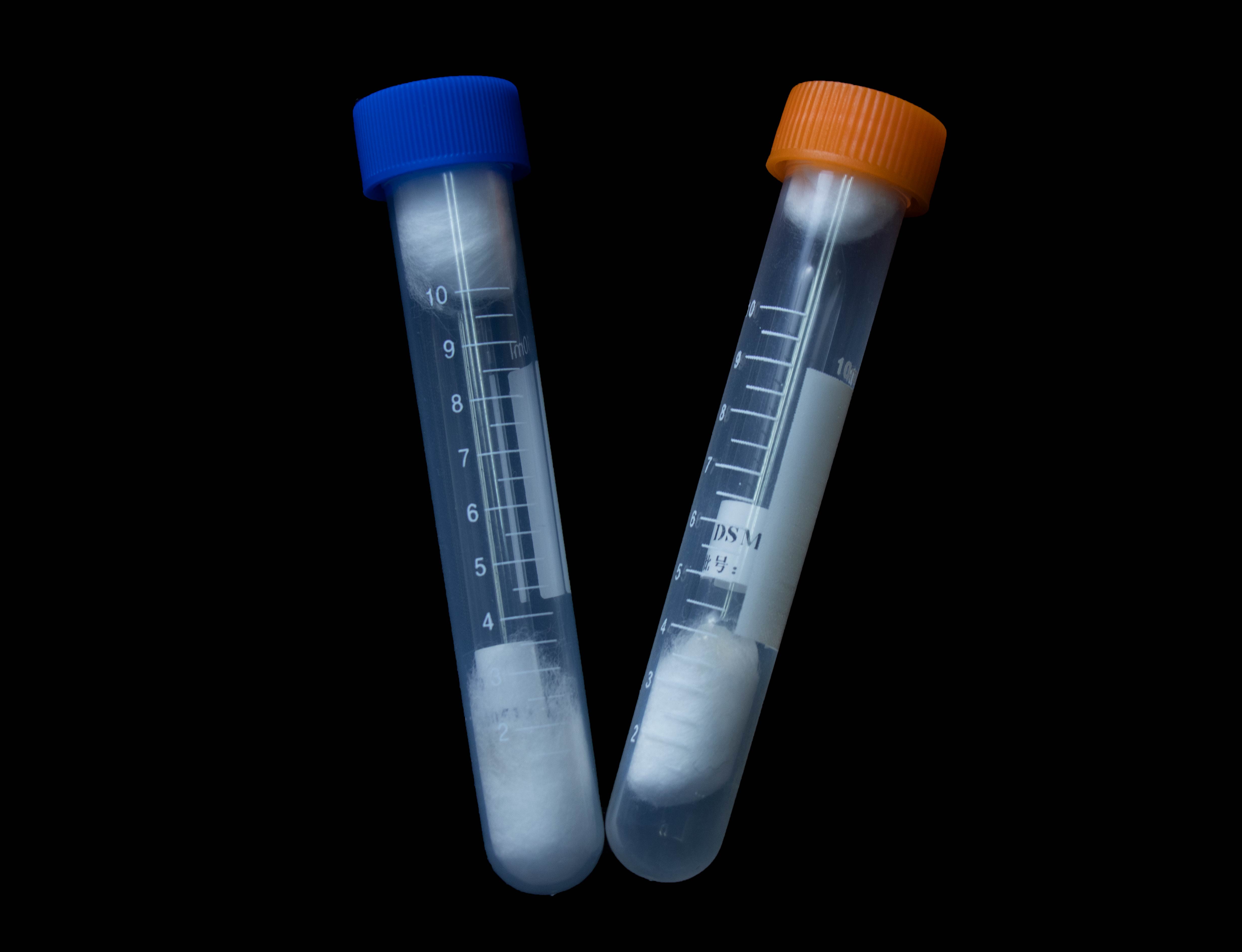
斜面

甘油

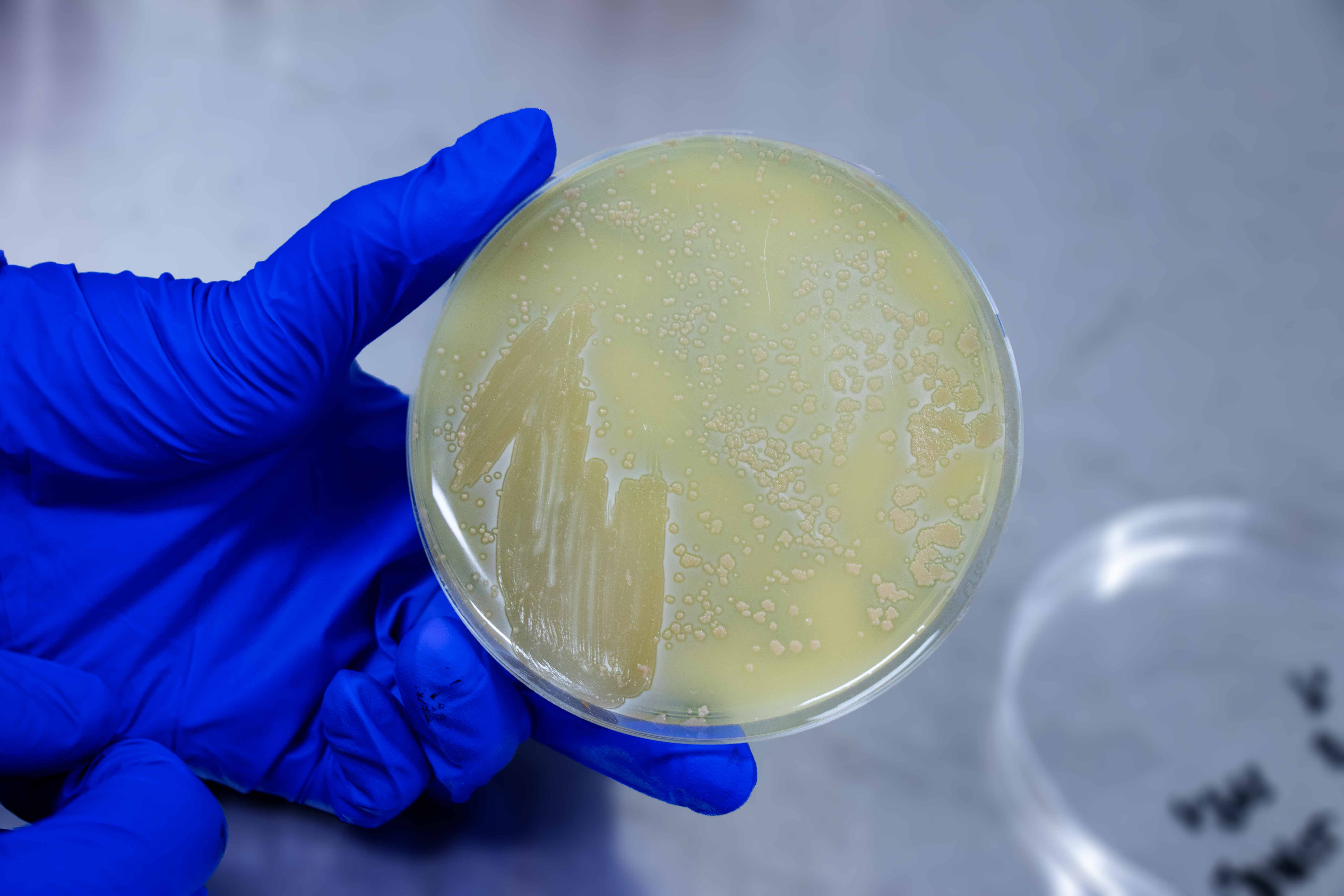
平板


| Product name: | Aspergillus insolitus |
| Testo id: | TS1002300 |
| Species Name: | Aspergillus insolitus |
| Type: | Polypaecilum insolitum |
| Synonyms: | Polypaecilum insolitum / Scopulariopsis divaricata / Scopulariopsis divaricata var. alba / Scopulariopsis insolita |
| Taxonomy: | FUNGI Ascomycota, Eurotiomycetes, Eurotiales, Aspergillaceae |
| Strain History: | C.J. La Touche (No. SC150) -> CBS 384.61 -> UAMH |
| Substrate: | ear, man |
| Isolator: | C.J. La Touche (No. SC150) |
| Isolation Date: | 1961-11-01 |
| Date Received: | 2010-08-03 |
| Characters: | CULTURE CONDITIONS grows better @ 30C than @ 35C - fide UAMH 2010 // MOLECULAR SYSTEMATICS phylogeny of Penicillium and related taxa in the Trichocomaceae - Houbrakken J, Samson RA, Stud Mycol 70:1-51, 2011 // PIGMENT yellow on PDA |
| Compounds: | |
| Cross Reference: | ATCC 18164 // CBS 384.61 // IFO 8788 // IMI 075202 // LSHB BB414 // MUCL 3078 // QM 7961 |
| Pathogenic Potential: | Human: yes | Animal: yes | Plant: no |
| Biosafety Risk Group: | RG2 (check the PHAC ePATHogen Risk Group Database for updates) |
| Regulatory Requirements: | Canadian requesters must provide PHAC Pathogen and Toxin License Number (see: https://www.canada.ca/en/public-health/services/laboratory-biosafety-biosecurity/licensing-program.html) prior to shipment. International requesters must provide all legally required importation documentation prior to shipment. Plant pathogenicity status may be verified by using the USDA Agricultural Research Service (ARS) Fungal Database |
| MycoBank ID: | 809591 |
| Sequences: | >UAMH11254_JN121911_Cct8 ACCCAGAAGGCCAAGGTGGGCGTGTTTAGCTGCCCAATTGATGTTAGCCAGACCGAGACCAAGGGAACAGTGCTTTTGAAGAACGCGCAGGAGATGCTCGACTACACTAAGGGAGAGGAGGAACGTCTTGAGGCGGCTATCAAGGAACTCTACGATTCGGGGATTCGTGTGGTCGTTGCGGGTGCGACTGTCGGTGACCTAGCTCTCCACTACCTTAACCGCTTCAATATTCTTGTGATTAAGATCTTGTCGAAGTTCGAGCTCCGCCGACTCTGCCGTGTCGTCGGTGCTACGCCTCTTGCTCGTTTGGGGGCACCTATGCCGGACGAGATGGGTAGCGTGGATGTGGTCGAGACCACGGAAATTGGCGGAGACCGAGTCACCGTGTTCCGTCAAGAAGACCCCAACACTGTCACACGCACAGCTACCATCGTCCTGCGTGGAGCGACCCAGAACCACCTGGAGGACGTCGAGCGTGCTATTGACGACGGGGTTAACGCTATCAAAGCGATCACCAAGGACCCGCGTCTCGTTCCTGGCGCTGGAGCCACTGAGATCCAGCTCTTAGAACGAATCTCGGCGTTTGCGGACAAGACGCCTGGGCTACCCCAGCATGCGATTCGGAAGTTCGCCGAGGCGTTCGAAGTGATTCCTCGTACGCTTGCCGAGTCTGCCGGGTTAGATGCCACGGAGGTGCTTTCTCGCCTGTACACA >UAMH11254_ITS CATTACCGAGCGTTTGGCAGCCCTGTTCCAGGGTTGCCTACCTCCCACCCGTGACTACCGTACCTTGTTGCTTCGGCGGGCCGCCGTCAGGCCCCCGGGGCGGGGGAGAAATCCCCCCCCTTCCGGGGCAGCGCCCGCCGGAGACACCTTGAAACTCTTTGTGTGAAGATTGCCTCTGAGTTTGACACAAAATAGCCAAAACTTTCAACAACGGATCTCTTGGTTCCGGCATCGATGAAGAACGCAGCGAACTGCGATAAGTAATGTGAATTGCAGAATTCAGTGAATCATCGAGTCTTTGAACGCACATTGCGCCCCCTGGTATTCCGGGGGGCATGCCTGTCCGAGCGTCATTGCTACCCTCCAGCACGGCTGGTGTGTTGGGCGCCGCGTCCCCTCCCCTTCCGGGGGGGACGGGCCCGAAAGGCAGCGGCGGCACCGTCCGGTCCTCGAGCGTATGGGGCTTTGTCACCCGCTCTGCAGGGCCGGCCGGGGCTCGCCTCGACAGTCAGTCTTCTTTTTTTTCTAAGGTTGACCTCGGATCAGGTAGGGATACCCGCTGAACTT >UAMH11254_JN121667_RNA polymerase II GTGTCTCCACAGCGAAATGGTCCCCTCATGGGTATTGTGCAAGATACCCTTTGTGGTATCTACAAGATTTGTCGGCGTGACGTTTTCCTATCCAGAGAACAAGTGATGAATATCATGCTCTGGGTTCCAGACTGGGATGGTGTTCTGCCACCGCCAGCTATTGTGAAGCCTCGGCCGCGATGGACCGGGAAGCAGATGATTAGCATGGCGCTTCCATCGGGTCTGAACCTCCTTCGTGTCGACAAGGACAATTCGGCTCTCTCCGAGAAGTTTTCCCCTCTTAACGATGGCGGATTGCTCATACACAGTGGACAGGTGATGTATGGAATGTTCTCTAAGAAGACTGTTGGCGCTAGTGGTGGTGGCGTTGTCCATACCATTTACAATGAGTATGGACCAGATGCTGCTGTCGCTTTCTTCAACGGCGCTCAGACCATTGTCAACTACTGGTTGTTACATCATGGGTTCAGTATTGGCATTGGCGACACGATTCCGGATCCGTCCACGATTCAGAGAATCGAGAATTGTGTTCGCAACCGCAAACAGGAAGTCGAATCTATAACCGCGAGTGCGACTGATAACACTCTCGAGGCGTTACCCGGTATGAATGTGCGAGAAACTTTCGAAAGCAAGGTCTCGCGTGCCCTCAACAATGCCCGTGATGAAGCTGGTGGCGAAACCGAGAAGAGCTTGAAGGATCTTAACAACGCCATCCAGATGGCACGTTCTGGATCCAAGGGATCGACTATTAACATTTCCCAGATG >UAMH11254_JN121510_RNA polymerase II AGGTGTGTTGAGAGTGGCAAGGATATTTATATGAATATTGGTGTAAAGGCCAGCACGTTGAGCTCGGGCTTGAAGTATGCTCTTGCCACAGGAAACTGGGGTGAGCAGAAGAAGGCAGCAAGCTCGAAGGCTGGTGTGTCGCAAGTACTCAGTCGATACACCTACGCGTCTACATTGTCACATCTTCGCCGGACCAACACGCCCATCGGCCGTGACGGAAAGATCGCGAAGCCACGCCAGCTTCACAACACGCACTGGGGCTTGGTCTGTCCGTCCGAAACTCCGGAAGGTCAAGCCTGCGGTCTCGTGAAGAATCTGGCGCTCATGTGCTACATCACCGTTGGTACGCCCAGCGAGCCGATCATCGACTTCATGATCCAGCGCAACATGGAGGTACTCGAGGAGTTCGAGCCCCAGGTGACGCCGAATGCAACAAAGGTGTTTGTGAACGGTGTCTGGGTAGGAATCCACCGTGATCCGTCTCATCTTGTTAACACCATGCTGTCGCTGCGCCGGCGGAACATGATTTCGCACGAGGTCAGTTTGATTCGGGACATCCGAGAGCGGGAGTTCAAGATCTTCACGGATGCCGGCCGTGTATCACGACCGCTGTTCGTTATCGACAACGACCCGAAGAGCGAGAACTCCGGCTCGTTAGTCCTTAATAAAGAGCATATCCGTAAATTGGAGGAAGATAAGGAATTGCCGCCCGACCTGGACCCCGAAGAGCGGAGAGAGCGCTATTTCGGATGGGATGGTCTTGTCAAATCTGGAGTTGTCGAATATGTCGATGCTGAGGAAGAGGAGACGATCATGATCGTGATGACCCCTGAAGACCTCGAGATCTCCAAGCAGCTTCAGGCCGGATATGCTCTTCCCGTGGAGACGGATCCGCACAAGCGAGTCCGGTCGATTCTCACGCAAAGGGCACATACGTGGACGCACTGCGAA >UAMH11254_JN121816_Tsr1 CTGAGTCGGTGGGAGACATCCGAGGACCGCCCACACGAACCTGAAGATTGGCGTCGACTGCTTCAAATTGCTGATTATAAGGGCTCCAAAAACAAGGCTATCAGAGAAGCACTGGTTGGAGGTGTCGACCCTGGAAACCGTGTCGACGTTCACCTTCGGGCAGTACCAGCATCCCTTCGCAATCGGCCACAGCCAGTGTCCCTTTTCTCCCTCCTCCGCCATGAGCACAAACAGACAGTTGTCAACATAAGCATGTACCTCCACTCTGACGTCGAGGCACCCCTGAAGTCTAAGGAAGAGCTTCTCATCCAATGCGGACCACGCCGTCTGGTCGTGAACCCTATCTTTTCCGCCGGAGGCGTGACTCCAAACAACGTCCACAAATTCGACCGCTTCCTCCACCCCGGCCGGAGTGCCATCGCATCCTGGATCGGGCCTATGACCTGGGGTTCAGTGCCTGCCCTCGTCTTCAAAAACAAGCAAGTCCAAGACCCCGAAGTGATGGACTCAGCCGACGAAAACTCCGAGAACAAACCGACCATCGACCAACTGCAGCTGATCGGAACCGGAACCGTCGTCGCGCCTGACCAGTCTCGAGTCGTCGCCAAGCGAGCTATC |